鲁晨光中文主页 English Homapage Papers on ArXiv Recent papers about Semantic Information and Statistical Learning
2025年4月于英文Open期刊Entropy发表英文综述文章 :《香农信息论的语义推广(G理论)和应用》
Entropy 是MDPI出版公司出版的一个专业期刊,汇集了全球许多对熵和信息感兴趣的作者和读者。这篇是我在Entropy上面发表的第5篇文章。
下面是中英文版。
|
中文综述文章:
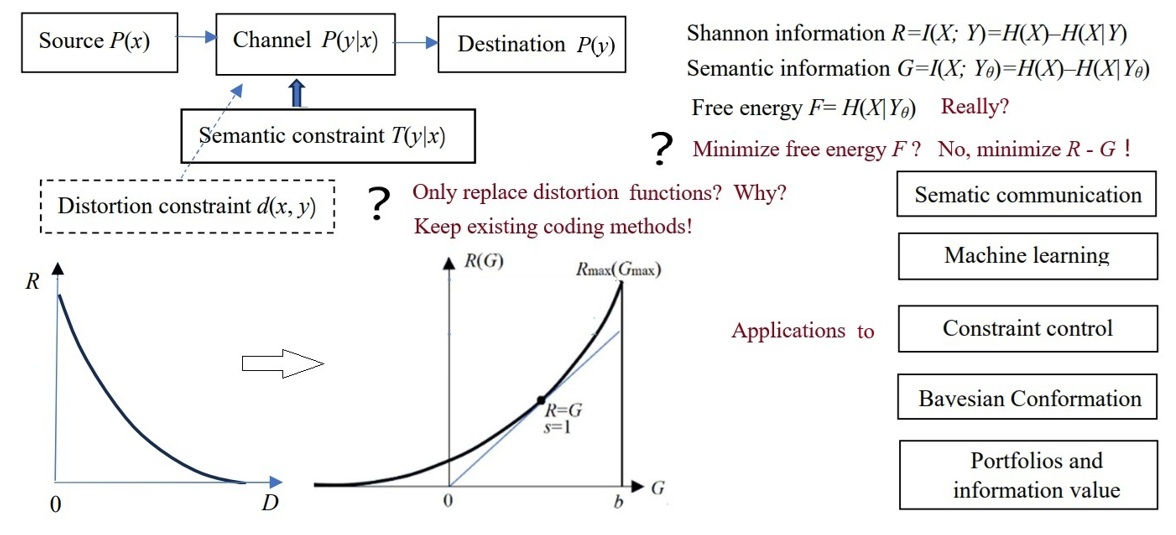
摘要:语义通信是否需要一个和香农信息论平行的语义信息论,还是只需要在香农信息论基础上推广?作者主张后者。语义信息G理论就是一个推广香农信息论得到的语义信息论。推广的方法是:仅仅添加语义信道,它由一组真值或隶属函数构成。通过真值函数可以定义语义失真,语义信息量和语义信息损失。语义信息量就等于Carnap和Bar-Hillel的语义信息量减去失真量, 最大语义信息准则等价于最大似然准则,类似于正则化最小误差平方准则。本文显示了G理论用于语义的和电子的语义通信,机器学习,约束控制,贝叶斯确证,投资组合和信息价值。改进机器学习方法涉及多标签学习和分类、最大互信息分为类,混合模型,求解隐含变量。文中还通过统计物理学分析,得到有意义结论:香农信息就相当于自由能,语义信息就相当于局域平衡系统的自由能和做功能力;最大信息效率就相当于用自由能做功时的最大热功效率;Friston的最小自由能原理可以改进为更加易于理解和使用的最大信息效率原理。文中联系投资组合理论讨论了信息价值。文中比较了G理论和其他语义信息理论的区别和联系,讨论了它表示复杂数据语义的局限性。
关键词: 语义信息论,语义信息测度,信息率失真,信息率逼真,变分贝叶斯,最小自由能,最大信息效率,投资组合,信息价值,约束控制. 。
|
English
Review:
A
Semantic Generalization of Shannon's Information Theory and Applications Abstract:
Does semantic communication
require a semantic information theory parallel to Shannon’s
information theory, or can Shannon’s work be generalized for
semantic communication? This paper advocates for the latter and
introduces a semantic generalization of Shannon’s information theory
(G theory for short). The core idea is to replace the distortion
constraint with the semantic constraint, achieved by utilizing a set
of truth functions as a semantic channel. These truth functions
enable the expressions of semantic distortion, semantic information
measures, and semantic information loss. Notably, the maximum
semantic information criterion is equivalent to the maximum
likelihood criterion and similar to the Regularized Least Squares
criterion. This paper shows G theory’s applications to daily and
electronic semantic communication, machine learning, constraint
control, Bayesian confirmation, portfolio theory, and information
value. The improvements in machine learning methods involve
multi-label learning and classification, maximum mutual information
classification, mixture models, and solving latent variables.
Furthermore, insights from statistical physics are discussed:
Shannon information is similar to free energy; semantic information
to free energy in local equilibrium systems; and information
efficiency to the efficiency of free energy in performing work. The
paper also proposes refining Friston’s minimum free energy principle
into the maximum information efficiency principle. Lastly, it
compares G theory with other semantic information theories and
discusses its limitation in representing the semantics of complex
data.
|
Graphical摘要:

