From the view-point of the generalized communication model, systems for weather forecasts, disease diagnoses, pattern recognition, and the like are all communication systems. To optimize these systems, we need proper assessing criterion. The assessing criterion that first calls to mind is probably the correctness rate. However, this criterion is generally unreasonable. For example, if one always predict “Tomorrow will not be rainy” or “You do not have AIDS”, the correctness rate of his predictions will be more than 70% and 99% respectively. However, this type of prediction has no value. If the stock index goes up today, and the prediction “The stock index will go up tomorrow” is offered, the correctness rate would be over 60% based on historical data. However, to the investor this prediction carries little value. To predict a numeric value like a stock index, squared-error criterion is often used; yet, it has similar defect.
From general perception of the term “information”, using information measure as the assessing criterion is reasonable. However, Shannon's information measure is also not suitable as the assessing criterion. It is for this reason that classical information theory does not adopt information criterion for assessing detection. From Figure 4 and the following examples the generalized information measure is shown to be an effective assessing criterion most cases.
![]() , (36)
, (36)
It can be proven that I(X;yj ) will reach the maximum when equation (37) below is tenable.
Q(xi|Aj )=Q(xi|z), i=1, 2, ..., n (37)
Q(Aj |xi)=C’Q(z’|xi), i=1,2,...,n (C’ is a constant), (38)
We may regard the curve Q(z’|X) as a value taken by the source and curve Q(Aj |X) as a value taken by the destination. In communication that the classical theory deals with, the values taken by source and destination are points; however, in the generalized communication we consider now, outputs from source and inputs to destination are lines . The more identical the areas the two curves cover and the smaller the areas, the more the information. The above method of selecting sentences is seemingly suitable for quantum detection in photon communication (Helstron, 1976).
![]() according to xt-1,
xt-2,...,
xt-k
(
according to xt-1,
xt-2,...,
xt-k
(
![]() is the predictive value of xt), then transmit Dt=xt-
is the predictive value of xt), then transmit Dt=xt-
![]() instead of
instead of
![]() . At the receiving end, the receiver can calculate
. At the receiving end, the receiver can calculate
![]() in the same way and have
xt=Dt+
in the same way and have
xt=Dt+
![]() . Since Dt
has smaller uncertain extent than xt,
its Shannon's entropy must be smaller than the Shannon entropy of xt, hence only shorter average code length is needed.
. Since Dt
has smaller uncertain extent than xt,
its Shannon's entropy must be smaller than the Shannon entropy of xt, hence only shorter average code length is needed.
Up to now, the assessing criterion of the prediction or predictive rules is subjectively selected. A popular criterion is the squared-error criterion. For example, in linear prediction:
![]() =a1xt-1+a2
xt-2+...+ak xt-k
, (39)
=a1xt-1+a2
xt-2+...+ak xt-k
, (39)
a group of coefficients a1, a2, ..., ak is most acceptable if it makes Equation (40) below to reach a minimum:
![]() . (40)
. (40)
![]() r=1, 2, ..., k,
(41)
r=1, 2, ..., k,
(41)
from which we can produce solution for a1, a2, ..., ak.
With the above criterion, whether to correctly predict an occasional event or a recurring event, the assessment will be the same. This criterion is very similar to the criterion of personal selection: “no error means virtue”. It encourages conservative predictions rather than information-rich predictions. In relation to predictions of weathers and stock indices such a criteria lacks usefulness. The criterion of personal selection we need should be that of “more attainments and fewer errors mean virtue”. The generalized information criterion exhibits such quality (Figure 4).
In predictive coding, we need to measure
information conveyed by
![]() about xt.
Let X stand for xt
, Z for a vector Xk=(xt-1,
xt-2,
..., xt-k),
Y
for
about xt.
Let X stand for xt
, Z for a vector Xk=(xt-1,
xt-2,
..., xt-k),
Y
for
![]() ; then the predictive information
is the generalized mutual information between Y and X.
; then the predictive information
is the generalized mutual information between Y and X.
From Section 4.2, we can see that it is consistent with the aim of compressing average code length to use the generalized information as the criterion of assessing the prediction. This criterion needs fuzzy prediction. For example, we use yj to denote a sentence “X approximately equals xj” or “X belongs to fuzzy set Aj”. We can first derive Q(X|Aj) from Q(Aj|X) and Q(X) and then code X according to Q(X|Aj ) so that the average code length is near the generalized condition entropy H(X|Y). Considering sequential information as t varies from 1 to T we have the generalized mutual information
![]() . (42)
. (42)
Assume Q(Aj|X) is a hill-like function:
![]() , (43)
, (43)
where
yt is
![]() defined by Equation (39); dt
is predicted by equation
defined by Equation (39); dt
is predicted by equation
dt=b1xt-1+b2xt-2+...+bk xt-k. (44)
Let the partial derivative of I(X;Y) with respect to ar, br for r=1, 2, ..., k be zero; we have 2k equations
![]() (45)
(45)
![]() (46)
(46)
From this group of equations we can deduce the solution for the 2k coefficients. If dt takes one of m' values, then we only need m' coding dictionaries for coding X. Yet, it is generally impossible to code X directly according to P(X|Xk), for which mk coding dictionaries are needed. It can be proven that if dt is constant and Q(X|At) is normal function, then Equation (42) reduces to Equation (40), which means the squared-error distortion criterion is a special case of the generalized information criterion.
For the prediction of a stock index, we may use similar method to select the information-richest prediction. For the predictions of other sequential signals, such as rainfall, quality of products, etc. the generalized information criterion would yield more satisfying results than the average squared-error criterion.
In the classical communication theory,
detection is to make a judgment yj
=
![]() =X=xj
according to Z=z’.
Generally, X and Y are discrete while
Z is continuous (Figure 6 shows binary
detection, a special case of detection). How to determine the line of
demarcation of judgments depends on what detection criterion is used. In the
classical communication theory, men-defined profit and loss (simply called loss)
is used as the criterion. That is, for each pair of xi and yj
, we define a loss function c(xi, yj
). The detection that
makes the average loss, Equation (47), to reach a minimum is the most
acceptable:
=X=xj
according to Z=z’.
Generally, X and Y are discrete while
Z is continuous (Figure 6 shows binary
detection, a special case of detection). How to determine the line of
demarcation of judgments depends on what detection criterion is used. In the
classical communication theory, men-defined profit and loss (simply called loss)
is used as the criterion. That is, for each pair of xi and yj
, we define a loss function c(xi, yj
). The detection that
makes the average loss, Equation (47), to reach a minimum is the most
acceptable:
![]() . (47)
. (47)
The function c(xi,yj ) only can be determined from experience or subjective selection. In most cases, the squared-error (xi-yj)2 is used as loss function.
The generalized information I(xi; yj ) can be used as an assessing function for the detection instead of the loss function in most cases where information value has not been taken into consideration. That is to say, a judgment yj that makes Equation (48) below to reach a maximum is the most acceptable.
![]() . (48)
. (48)
In Equation (48), Q(Aj|xi) is the probability of confusing xi with xj (refer to Figure 1).
Disease diagnosis is a similar case. For example, a medical assayer judges whether a patient’s tested datum showing some disease, say AIDS, is positive. In this case, XÎA={x0=no-AIDS, x1=AIDS}; YÎB={y0=“The assay is negative”, y1=“The assay is positive”}; Z is the tested datum (Figure 6). This binary detection is very similar to the detection of 0-1 codes in electric communication.
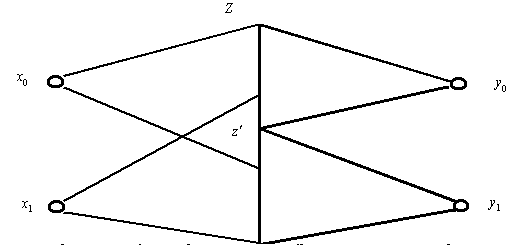
Figure 6 Binary
detection for digital communication and disease diagnosis
Now consider the Bayesian detection in
the generalized information theory with a binary source as an example. In
classical communication theory, Bayesian detection
derived from complicated
deduction is in this way (Rosie, 1978): if
![]() , cij=c(xi,
yj), i, j=0,1,
(49)
, cij=c(xi,
yj), i, j=0,1,
(49)
then we judge “ X=x0” or let Y=y0; otherwise judge “X=x1” or let Y=y1. Now we use the generalized information measure as criterion for the detection. From Equation (48), the judgment should be that if I(X; y0)>I(X; y1), i. e.
![]() , Iij =I(xi;yj
), i,
j=0, 1 (50)
, Iij =I(xi;yj
), i,
j=0, 1 (50)
then we let Y=y0; otherwise, let Y=y1.
How do we determine Iij ? One way is first to determine the confusion probability Q(Aj|xi) for i, j=0, 1. Another way is that, for example, from the statistics of physicians, to whom the assaying results will be sent. We get past objective probability P*(X) and objective condition probability P*(X|yj ). L et Q(X)=P*(X) and Q(X|Aj )=P*(X|yj ), from which we can calculate Iij.
Generally, people think that the absolute value of the loss from a wrong judgment is greater than the absolute value of the profit from a correct judgment. The generalized information criterion happens to have this asymmetrical feature (see Section 6.2). Hence, in most cases, the generalized information criterion is enough for the assessments and the consideration of profit and loss or information value is unnecessary.
If A and B are also continuous, then the detection will become an estimation. We can regard estimation as a special case of detection as m approaches infinity.