In the classical information theory, the
amount of information conveyed by yj
about xi
( assume yj really
appears corresponding to xi
) is
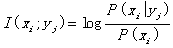 . (12)
. (12)
In linguistic communication, generally
we do not know P(xi) and P(xi|yj ). What we can know is Q(xi) and
Q(xi|yj is true)
from experience and the linguistic meaning of the sentence. Therefore, the
selective probability of yj should
be replaced with its logical probability. Extending Equation (12),
the amount of information is represented by Equation (14)
if and only if xi appears corresponding to a prediction yj.
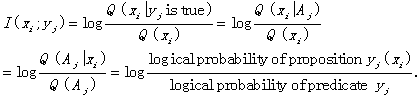 (13)
(13)
The above formula of semantic
information can ensure that 1) the smaller the prior logical probability of yj
is and the greater the posterior logical probability of yj
(or say logical probability of proposition yj (xi)
is ), the more information yj
conveys; otherwise, the less (probably negative) information
yj conveys;
2) the fuzzier the sentence yj is,
i.e. the closer Q(Aj |X) is to Q(Aj
), the smaller the absolute value of the information is. We use an
example to test Equation (13).
Example
3.2.1 We need to predict a stock index for the
next weekend. Assume x0=100
is the current index; two predictions are yj
=“The index will be about xj”
and yk=“The index will be
about xk”; there is prior
knowledge:
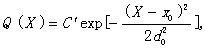 where C’ is a
normalizing constant;
where C’ is a
normalizing constant;
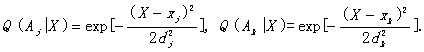

Figure 4
Information I about stock index X
conveyed by different predictions yj
and yk
Figure 4 shows the changes of
information conveyed by yj and
yk respectively with X
changing It tells us that the more an occasional event is correctly predicted,
the more the information. The dashed lines show the case in which dj is
reduced. The corresponding prediction may be expressed as “The index will be
very closed to xj ”. It
is said that when predictions are correct, the more precise the prediction is,
the more the information is. If a prediction is extremely fuzzy such as “The
index will probably go up or not go up”, Q(Aj|X) can be represented
by a horizontal line and the information will always be zero.
For semantic information or predictive
information, we can calculate the average information conveyed by
yj about
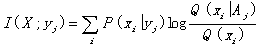 . (14)
. (14)
This equation is similar to the
generalized Kullback formula proposed by Thail (1967). The information I(X;yj) can be
pictorially represented with the
help of Figure 5.
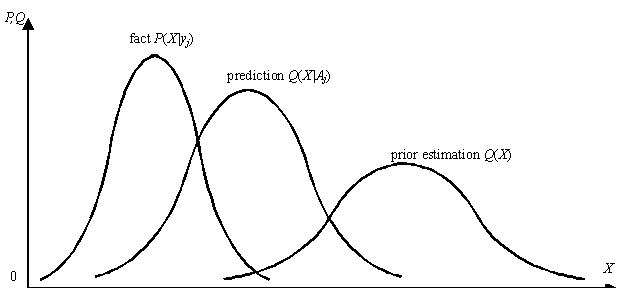
Figure 5 Illustration of
information I(X; yj)
When the fact or objective probability P(X|yj
) ( i.e. P(xi|yj
) for i=1, 2, ..., n) is given,
if the posterior forecast or the posterior subjective probability Q(X|Aj
) is closer to the fact than the prior forecast or the prior
subjective probability Q(X),
then the information is positive; otherwise, the information is negative or
zero. When the prior forecast Q(X)
is given, the more conformable the posterior forecast Q(X|Aj
) is with the fact P(X|yj
), the more information yj conveys.
When Q(X|Aj
)=P(X|yj ), I(X;
yj ) reaches its maximum:
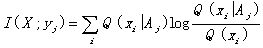 . (15)
. (15)
Further more, if Q(X)=P(X), the above
information will become Kullback's information (1959).
Equation (14) and the following
generalized mutual information formula (Equation (17 ))
also can be used to measure information conveyed by measurement
instruments or sensors.
Example
3.2.2 The reading of a platform balance for
selling apples is probably not accurate. Let random variables X and Y denote
actual weight and scale
reading respectively. Assume that, to a buyer, the possibility distribution of
forecasted weight is Q(X) before balancing,
and Q(X|Aj ) after balancing; the probability distribution of
actual weight obtained with a standard balance is P(X|yj ). Then, the information conveyed to a buyer
can be measured with Equation (14). If the reading of the balance is
always greater than actual weight and a buyer believes it, the information will
probably be negative.
If the prediction yj is
always made when Z=z’, then the above equation will become
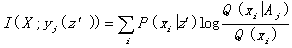 . (16)
. (16)
To calculate the expectation of I(X;yj
), we have the formula of generalized mutual information:
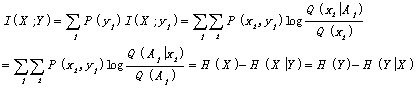 . (17)
. (17)
where H(Y)
is the generalized entropy of Y (as
seen in Equation (9)); H(X)
is the probability-forecasting entropy of X:
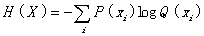 . (18)
. (18)
A similar form was proposed by Aczel and Forte (1986). H(Y|X) is fuzzy entropy or
generalized condition entropy of Y,
and H(X|Y) is generalized
condition entropy of X.
These are
 , (19)
, (19)
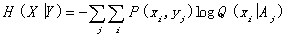 . (20)
. (20)
Let us call a sentence yj vaguely
true if Q(X|Aj )=P(X|yj
). When sentences y1,
y2, ..., ym are all vaguely true, H(X|Y) returns to the Shannon condition entropy. If at the same time Q(X)=P(X),
the generalized mutual information will return to Shannon's mutual information.
Consequently it may be thought that
Shannon’s information is objective information and the generalized information
is subjective information; the former is the special case of the latter as
subjective forecast conforms with objective facts.
When the information source is constant,
i.e. Q(X)=P(X), the generalized mutual information reaches its maximum and is
equal to Shannon's mutual information as the sentences are vaguely true, which
means that when information is
conveyed from the object to the subject, information can not increase but
decrease.
It can be
proven that if the language is extremely fuzzy,
i.e. Q(Aj
|xi)=Q(Aj
) for i=1, 2, ..., N, then H(Y|X)=H(Y),
I(X;Y)=0;
if the language is extremely clear and correct, i.e.
Q(Aj
|X)Î{0,1}
and Q(X|Aj
)=P(X|yj ) for j
=1, 2, ..., n, then
H(Y|X)=0, I(X;Y)=H(Y).
If the language is extremely clear and
incorrect, then
H(Y|X)=¥,
I(X;Y)=
-¥.
Since, one never thoroughly eliminates
suspicion about a prediction; therefore, perfectly clear linguistic meaning and
infinite mis-information do not
really exist.
If P(xi)=1/m for i=1, 2, ..., m
and assume there are only two complementary sentences in the set B,
and the sentences are correctly used, then P(yj
|X)=Q(Aj |X) for j=1,
2, H(Y|X) reduces to De
Luca and Termini's fuzzy entropy (1972).