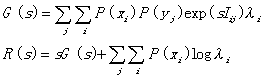 , (51)
, (51)
The Rate-of-keeping-precision theory is a reformed version of the rate-distortion theory in classical information theory . It is a theory for datum compression like the rate-distortion theory as well as a theory for matching an objective channel with subjective understanding or discrimination.
The rate-distortion theory may be revised by replacing the upper limit of distortion D ( Equation (22) ) with the lower limit of generalized information to seek the minimum of Shannon's mutual information. Let the lower limit of the generalized mutual information be G, dij be replaced with Iij =I(xi; yj ), and D be replaced with G. Then the rate-distortion function R(D) will become function R(G), which is called rate-of-keeping-precision function and also has coding meaning. In the rate-distortion theory, D can only be positive, whereas G can also be negative. We use keeping-precision instead of fidelity or limiting-distortion because the new criterion for communication quality emphasizes precision rather than correctness only.
In a way similar to that in the classical information theory (Berger, 1971), we can obtain the expression of function R(G) with parameter s:
, (51)
where s=dR/dG, which means the necessary increment of objective information when subjective information is needed to increase (Figure 7 and 8), indicates the slope of function R(G); and
![]() .
.
In linguistic communication, coding is expression and decoding is understanding. We often mention the price of some goods by saying “more than thirty Dollars” instead of “thirty-two Dollars and fifteen Cents”, mention someone's age by saying “over thirty years old” instead of “thirty-three years and five months old”. This is because the more accurate a datum is, the more objective information it conveys and it is more difficult to memorize it. However, by using inaccurate or fuzzy language, we can use less objective information to convey enough subjective information. In other words, we increase the relative amount of subjective information by decreasing its absolute amount.
Function R(G) indicates the compressing limit of objective information for certain subjective information. For sensory communication, such as image communication between men and machines, function R(G) has much more practical meaning. For example, it tell us that it is not necessary for the TV to have a very high resolution when the viewing distance cannot be very short and hence the spatial discrimination of men’s eyes is limited. By the same token, a digital black-and-white image with too many gray levels for a given visual discrimination is also not necessary (Figure 9 and 10).
First we use a binary source with symmetrical similarity relation ( Q(Aj|xi)=Q(Ai|xj)i, j=0,1 ) as example to examine the properties of function R(G). In this case, function R(G) can be directly resolved. Given the lower limit of subjective information
![]()
![]() (52)
(52)
we can have the solution of function R(G) as:
![]() . (53)
. (53)
The deduction of function R(D) of binary memoryless source in classical information theory (Berger, 1971) can be referred to for the deduction of function R(G).
Assume P(x0)=P(x1)=0.5, Q(X)=P(X), and the similarity relation
![]() , i, j=0, 1,
, i, j=0, 1,
then b=0.817, a= -2.069. The function R(G) is shown in Figure 7.
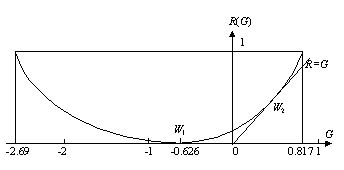
Figure 7 Rate-of-keeping-precision
function of a binary source
In Figure 7, R(-0.626)=0 as shown by Point W1 which means that if Y has nothing to do with X whereas one still believes Y is the correct response of X, then the average loss of subjective information is at least 0.626 bits. Of course, if we know that Y has nothing to do with X, then the set Aj will be extremely fuzzy and there should be no information loss. A similar example in daily life is that if one believes a fortune teller’s talk, one would be more ignorant about facts and the information one has will be reduced. If one does not believe fortune telling, then one will have no information loss.
With G increasing from Point W1, R increases; and its maximum is R(0.817)=1. When G decreasing from Point W1, R also increases. This tells us that for intentionally increasing someone’s information loss, we would increase corresponding objective information In other words, lies about real situations are more harmful than lies at random.
When s=1, equation Q(X|Aj )=P(X|yj ) for j=0,1 is tenable so that R=G=0.473. In this case, objective information (Shannon’s information ) is equal to subjective information. We call
![]() (54)
(54)
information efficiency. Then G/R is the upper limit of g , and reaches 1, its maximum, at Point W2.
Since P(yj|xi), li and P(yj ) for i, j=1, 2, ..., m rely on each other, the exact solution of function R(G) can be found only in special cases as shown in the last section. Generally, function R(G) can only be resolved by the iteration method. The procedure for the iteration method is shown as follows ( Q(X)=P(X) is assumed):
1) Calculate I(xi; yj ) for i, j=1, 2, ..., m;
2) Give the initial value s0 and the final value s1 of s; for example, let s0= -10, s1=10, s=s0.
3) Set the initial values R0 and P'ji of R and P(yj |xi) for i, j=1, 2, ..., m. For example, let R0=100, P'ji=P(xi).
4) Calculate P(yj ) and li for i, j =1, 2, ..., m.
5) Calculate the new values of Pji =P(yj |xi) for i, j=1, 2, ..., m and R=Is(X;Y).
6) Let r=|R-R0|/R0. If r>e ( such as , e=0.001), let R0=R, P'ji=Pji for i, j=1, 2, ..., m and return to 4); otherwise, calculate G and print s, R, and G.
7) Let s=s+step_length. If s<s1, then return to 3); otherwise, end the calculation.
The general properties of rate-of-keeping-precision may be examined by an image communication example. Assume we need to quantize an analog image into a numerical image and then to code, to transmit or store, and to decode the digitized image. The decoded image will be displayed for viewers; it has the same gray grades as the digitized image . For convenience, only information conveyed by a pixel of the image is considered. The problems to be resolved for optimizing image communication are
1) For a given subjective visual discrimination and the lower limit of subjective information, what is the shortest average code length?
2) For given subjective discrimination, how many quantizing grades of gray are needed to have enough subjective information and higher information efficiency?
Let the gray level of quantized pixel be a source and the gray level is X=0, 1, ..., b with probability distribution:
![]()
where C” is a normalizing constant, c=b/2, s0 = b/8. For simplicity, we assume that after decoding the pixel also has gray level Z=0, 1, ..., b; the perception caused by zj is yj ; the visual discrimination space is uniform (Lu, 1989); discrimination function or confusion probability function is
![]()
where d is discrimination parameter. The smaller d is, the higher the discrimination is.

Figure 8 shows the relationship between d and R(G) for b=63. The figure indicates that
1)When R=0, the smaller d is, i.e. the higher the discrimination is, the smaller G is. If decoded image has nothing to do with original image whereas one still believes the former exactly reflects the latter, then one’s subjective information will decrease; and the higher the discrimination, the greater the information loss.
2) The higher the discrimination, the greater the possible value of G matching R. In other words, to increase information efficiency, objective information should increase with the discrimination increasing so that the objective matches the subjective.
3) When G approaches its possible maximum, dR/dG is quite great. This means that if we want to increase the absolute value of subjective information, we have to sacrifice its relative value; this is often uneconomical.
4) For given R, there is the optimal discrimination parameter d so that G=R. In fact, human brains are capable of improving information efficiency by changing subjective discrimination. To determine dt in the predictive coding as discussed in Section 4.2 is actually to modify subjective discrimination of a machine or a software..

Figure 9 Relationship between R(G) and
b for certain subjective discrimination ( d=1/64)
Figure 9 shows the relationship between R(G) and b when d=1/64. It is shown that when b becomes smaller, the possible maximum value of G and the matching value of G and R increase in an approximately direct ratio to the quantizing bit k=log2(b+1); when b becomes greater, its increase makes very little effect on G. In other words, for a given discrimination, it is not good for the quantizing grade b to be too small or too great. If b is too small, there isn't enough subjective information. If b is too great, it is uneconomical.

Figure 10 Relationship
between matching value of R
with G, discrimination
parameter d, and
quantizing bit k when s=1