In the following, it is shown that the generalized information theory is based on more general mathematical concepts in comparison of Shannon’s information theory.
1) Assume a prediction “Tomorrow will be rainy” has been made by an observatory for many times. We can derive the frequency ( or say percentage ), such as 70%, of rain from the statistics of objective facts. The frequency is called objective probability. The probability a prediction is selected is also derived from the statistics of objective facts and hence is also called objective probability. In the following, an objective probabilities is denoted by P( ).
Let a set of objects be A={x1, x2, ..., xm}, and a set of predicates be B={y1, y2, ..., yn}, X and Y be random variables taking values in A and B respectively. For example, A is a set of different ages and B is a set of predicates, such as “ X is about twenty ” ( X here means a room that will be filled with a person’s age denoted by xi, i=1, 2, ..., m). We use yj or yj(X) to stand for a predicate , and yj(xi) for a proposition. If X is given, such as X=x1 or X=Tom’s age, then the predicate will becomes a proposition: “Tom’s age is about twenty”. If a proposition is a judgment or conjecture about uncertain event, it is also called a prediction.
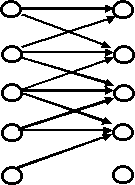
Following the random-set projection theory presented by Wang (1987), we may treat a fuzzy set as the statistical result of a random set (see Figure 1); and thus, the membership grade is defined as follows:
Definition
2.1.1 the membership
grade of xi in fuzzy subset Aj of A
is
Q(Aj
|xi)=P(XÎSj|X=xi)=P(xiÎSj)=
![]() , (1)
, (1)
where Q(Aj|xi) Î[0,1], Sj is a random set with respect to fuzzy subset Aj of A, sk is a given set as a value taken by Sj, Q(sk|xi) Î{0,1} is the feature function of set sk.

In this paper, the logical probability of proposition yj(xi), or logical condition probability of predicate yj is defined as the same as the membership grade, i.e.
Further, let the logical probability of the predicate yj be defined as
![]() Q(xi)Q(Aj |xi).
(3)
Q(xi)Q(Aj |xi).
(3)
![]() ,
,
![]() ;
;
![]()
in most cases.
![]() Q(xi)Q(A'|xi), (4)
Q(xi)Q(A'|xi), (4)
Q(xi|A')=Q(X=xi, XÎA')/Q(XÎA')=Q(xi)Q(A'|xi)/Q(A'). (5)
Bayesian formula. Let the clear set A’ be replaced with a fuzzy set Aj. Then we have set-Bayesian formula for fuzzy set:
Q(xi|Aj)=Q(X=xi|XÎAj)=Q(X=xi|XÎSj)
=Q(X=xi, XÎSj)/Q(XÎSj)=Q(xi)Q(Aj|xi)/Q(Aj). (6)
Table I mathematical concepts basing entropy and generalized entropy
| Shannon’s entropy | generalized entropy |
| set partition | set covering |
| mapping or regular mapping | generalized mapping |
| equivalence relation | similarity relation |
Let A1, A2, ..., An be subsets of A. The set AJ ={A1, A2, ..., An} is called a covering of A if
![]() . (7)
. (7)
|
relation generalized mapping mapping
|
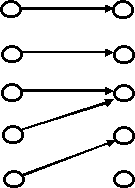
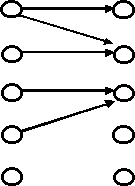
Figure 2 Illustrations of relation, generalized mapping, and mapping
It can be proven that a generalized mapping from A to B determines a covering of A, and a regular mapping on A´B determines a partition of A; vice versa (see Figure 2). Similarly, a generalized mapping from A to B determines a similarity relation on A´A, and a regular mapping from A to B determines a equivalence relation on A´A; and vice versa.
![]() , (8)
, (8)
where P(yj) is a objective probability in which the predicate yj is selected; Aj a set formed by all inverse image of yj; Q(Aj ), defined by Equation (3), is the logical probability of yj.
If the generalized mapping becomes a regular mapping, then Q(Aj )=P(yj ) for j=1, 2, ..., n, and hence the generalized entropy becomes Shannon’s entropy:
![]() . (9)
. (9)
A generalized mapping R from A to B can be determined by a m´n (m=|A|, n=|B|) matrix with elements r(xi , yj)Î{0,1} for i=1, 2, ..., m; j=1, 2, ..., n, where r(xi , yj)=1 means (xi , yj)ÎR. If r(xi , yj)Î[0,1], then we call R a fuzzy relation.
Definition 2.4.1 A fuzzy relation is called a fuzzy mapping (or fuzzy generalized mapping) if
![]() r(xi,
yj )³1,
i=1, 2, ..., m. (10)
r(xi,
yj )³1,
i=1, 2, ..., m. (10)
Definition 2.4.2 Assume R is fuzzy mapping and Q(Aj|xi)=r(xi, yj) for i=1, 2, ..., m; j=1, 2, ..., n. we call
![]() (11)
(11)
the generalized condition entropy.
In Equation (11), the condition probability P(yj|xi) for i=1, 2,..., m indicates the rule for selecting sentence yj; whereas logical probability Q(Aj|xi) for i=1, 2, ..., m embodies the meaning of sentence yj. The former changes from case to case and person to person. Yet, the latter is determined by linguistic culture. The former must be normalized; whereas the latter needn't be. The reason is that, in set B, there are probably two sentences, such as “Tomorrow will be rainy” and “Tomorrow will be very rainy”, that are equally true at the same time.
Example 2.4.1 Three kinds of possible weathers are x1=no-rain, x2 =light-rain, x3=heavy-rain; A={x1, x2, x3}; P(x1)=P(x2)=P(x3)=Q(x1)=Q(x2)=Q(x3)=1/3. There are sentences y1=“There is no rain”, y2=“There is light rain”, y3=“There is heavy rain”, y4=“There is rain”; B={y1, y2, y3, y4}. The selective condition-probability matrix and the logical condition-probability matrix of sentences are shown as follows:
{P(yj |xi) | i=1, 2, 3; j=1, 2, 3, 4} =
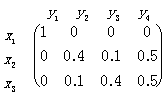 ,
,
{Q(Aj|xi)|i=1, 2, 3; j=1, 2, 3, 4} =
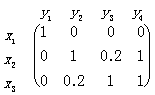 .
.
Q(A1)=1/3; Q(A2)=Q(A3)=1.2/3; Q(A4)=2/3;
H(Y)=
-
![]() P(yj)logQ(Aj)=1.16(bits)
P(yj)logQ(Aj)=1.16(bits)
H(Y|X)= -
![]()
![]() P(xi,
yj)log Q(Aj|xi)=
-0.1log0.2=0.46(bits);
P(xi,
yj)log Q(Aj|xi)=
-0.1log0.2=0.46(bits);
H(X;Y)=H(Y)-H(Y|X)=0.70(bits).
Definition 2.4.3 The subset R of the product set A´A is called a fuzzy similarity relation if
![]() rij for
j=1, 2, ..., m;
rij for
j=1, 2, ..., m;
2) R is symmetrical, i.e. rij=rji, i, j=1, 2, ..., m;
3)
![]() rij ³1.
rij ³1.
![]() rij=1.
rij=1.
Assume A
is a set of different gray levels or colors. The confusion probability in which xi
and xj are confused
by sight (or a detector) can be a
similarity function r(xi, xj).
Let
![]() represent a prediction yj=“X
is likely xj” and Aj be a fuzzy set including all X ÎA confused with xj. Then Q(Aj|xi)=r(xi,
xj ). In this case, we also call
Q(Aj|xi)=r(xi,
xj ) a fuzzy discrimination function. Treating r(xi,
xj) as logical condition
probability, we can calculate sensory information, which is conveyed by sense
organs or detectors, in the same way as semantic information. In practice, both
logical condition probability function Q(“yj
is true”|X) and
confusion probability function r(X,
xj ) can be obtained by the
set-valued statistics ( refer to Figure 1 and Equation (1)).
represent a prediction yj=“X
is likely xj” and Aj be a fuzzy set including all X ÎA confused with xj. Then Q(Aj|xi)=r(xi,
xj ). In this case, we also call
Q(Aj|xi)=r(xi,
xj ) a fuzzy discrimination function. Treating r(xi,
xj) as logical condition
probability, we can calculate sensory information, which is conveyed by sense
organs or detectors, in the same way as semantic information. In practice, both
logical condition probability function Q(“yj
is true”|X) and
confusion probability function r(X,
xj ) can be obtained by the
set-valued statistics ( refer to Figure 1 and Equation (1)).