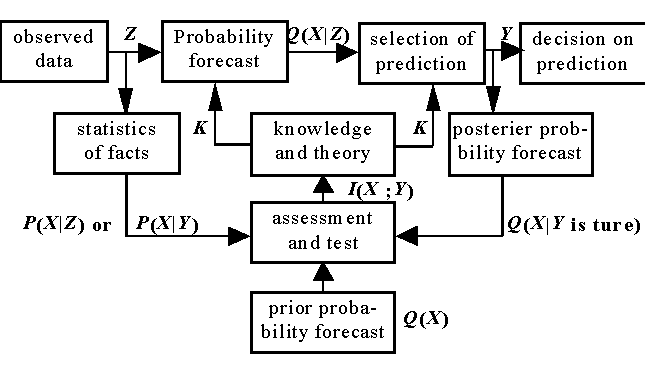
Figure 3 Generalized communication model
This section attempts to answer the following questions that classical information theory is not able to answer: 1) When we only know the past source and channel, a future source and channel might be different, how do we measure the information? 2) When we can only forecast the condition probability of a event that is subjective and might be more or less inconsistent with the facts, how do we measure the information? 3) When we only know the meaning of a message or a sentence without any idea about the objective condition probability, i.e. the channel P(Y|X), in which the massages or the sentences occur, how do we measure the information? For this purpose, we need a different communication model.
A theory, according to Popper , will be more acceptable if it has more information content, and has greater ability in predicting and explaining facts, and hence can undergo more severe tests in comparison of the predictions about facts with observations. In other words, we prefer an information-rich theory (Popper,1968, Chapter 10.1-II). Popper described qualitatively the criterion of progresses of scientific theories. The proposed generalized communication model (Lu, 1991b) conforms well with Popper's evolution mode of scientific theories.
Assume that probability or possibility distribution Q(X|Z), in which an objective event X will happen, is derived according to given condition Z and knowledge K ( K may be formed by databases and reasoning rules, Figure 3). Let Q(X|Z) be named subjective probability forecast. The probability forecast can also be indirectly provided by a prediction, perception, or detected signal. In that way, the probability forecast becomes Q(X|Aj).
Figure 3 Generalized
communication model
Let a set of objective events or objects be A={x1, x2, ..., xm}, a set of selected sentences be B={y1, y2, ..., yn}, a set of conditions or observational data be C={z1, z2,..., zl}, X, Y, Z be random variables taking values in sets A, B, C respectively. What is to be measured is information conveyed by Z or Y about X.
Let us use predictions about rain as an example. Let Z stand for meteorological data, K for meteorological knowledge or theory, Q(X|Z) for the probability distribution of different rainfalls forecasted according to Z and K, Y for a prediction, such as “It will be rainy” or “It will be very rainy”, Q(X) for the prior probability distribution of rainfalls forecasted by an audience before the prediction is made.
The method of testing the prediction Y (and K) is to see which of Q(X|Y is true) and Q(X) better conforms with P(X|Y) or P(X|Z). For simplicity, we also call P(X|Y) or P(X|Z) as the fact, Q(X|Y is true) or Q(X|AJ) as posterior forecast and Q(X) as prior forecast. If the posterior forecast is more conformable with the fact in comparison of the prior forecast, then Y is
valuable; otherwise, Y is useless or bad. To provide more information, the meteorological observatory improves their theory or reasoning rules again and again so that it can make more correct and more precise predictions. Not only weather forecasts advance in this way, ndiagnoses of a diseases or predictions of economic situations advance in similar manner.
In this model the most general information is predictive information. If equation Q(X|Z)= P(X|Z) is always tenable, then the predictive information will become the semantic information of describing facts. If the link of language is absent and the information is conveyed by Z instead of Y, then the predictive information will become the probability-forecasting information. If Q(X)=P(X) and Q(X|Aj )=P(X|yj ) for j =1, 2, ..., n, then the predictive information becomes Shannon's information. We can say that the Shannon information is objective information, whereas the generalized information is subjective information. The former is the special case of the latter when the subjective prediction always conforms with objective facts.